Databricks Integration
Audience: Data Owners and Data Users
Content Summary: This page provides an overview of the Databricks integration. For installation instructions, see the Databricks Installation Introduction.
Overview
Databricks is a plugin integration with Immuta. This integration allows you to protect access to tables and manage row-, column-, and cell-level controls without enabling table ACLs or credential passthrough. Policies are applied to the plan that Spark builds for a user's query and enforced live on-cluster.
Architecture
An Application Admin will configure Databricks with either the
- Simplified Databricks Configuration on the Immuta App Settings page
- Manual Databricks Configuration where Immuta artifacts must be downloaded and staged to your Databricks clusters
In both configuration options, the Immuta init script adds the Immuta plugin in Databricks: the Immuta
Security Manager, wrappers, and Immuta analysis hook plan rewrite. Once an administrator gives users
Can Attach To entitlements on the cluster, they can query Immuta-registered data source directly in their
Databricks notebooks.
Simplified Databricks Configuration Additional Entitlements
The credentials used to do the Simplified Databricks configuration with automatic cluster policy push must have the following entitlement:
- Allow cluster creation
This will give Immuta temporary permission to push the cluster policies to the configured Databricks workspace and overwrite any cluster policy templates previously applied to the workspace.
Policy Enforcement
Immuta Best Practices: Test User
Test the integration on an Immuta-enabled cluster with a user that is not a Databricks administrator.
Registering Data Sources
You should register entire databases with Immuta and run Schema Monitoring jobs through the Python script provided during data source registration. Additionally, you should use a Databricks administrator account to register data sources with Immuta using the UI or API; however, you should not test Immuta policies using a Databricks administrator account, as they are able to bypass controls.
Table Access
A Databricks administrator can control who has access to specific tables in Databricks through Immuta
Subscription Policies or by
manually adding users to the data source.
Data users will only see the immuta database with no tables until they are granted access to those tables as
Immuta data sources.
The immuta Database
When a table is registered in Immuta as a data source, users can see that table in the native Databricks
database and in the immuta database. This allows for an option to use a single database (immuta) for
all tables.
Fine-grained Access Control
After data users have subscribed to data sources, administrators can apply fine-grained access controls, such as restricting rows or masking columns with advanced anonymization techniques, to manage what the users can see in each table. More details on the types of data policies can be found on Data Policies page, including an overview of masking struct and array columns in Databricks.
Note: Immuta recommends building Global Policies rather than Local Policies, as they allow organizations to easily manage policies as a whole and capture system state in a more deterministic manner.
Accessing Data
All access controls must go through SQL.
df = spark.sql("select * from immuta.table")
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
val sqlDF = spark.sql("SELECT * FROM immuta.table")
%sql
select * from immuta.table
library(SparkR)
df <- SparkR::sql("SELECT * from immuta.table")
Note: With R, you must load the SparkR library in a cell before accessing the data.
Mapping Users
Usernames in Immuta must match usernames in Databricks. It is best practice is to use the same identity manager for Immuta that you use for Databricks (Immuta supports these identity manager protocols and providers. however, for Immuta SaaS users, it’s easiest to just ensure usernames match between systems.
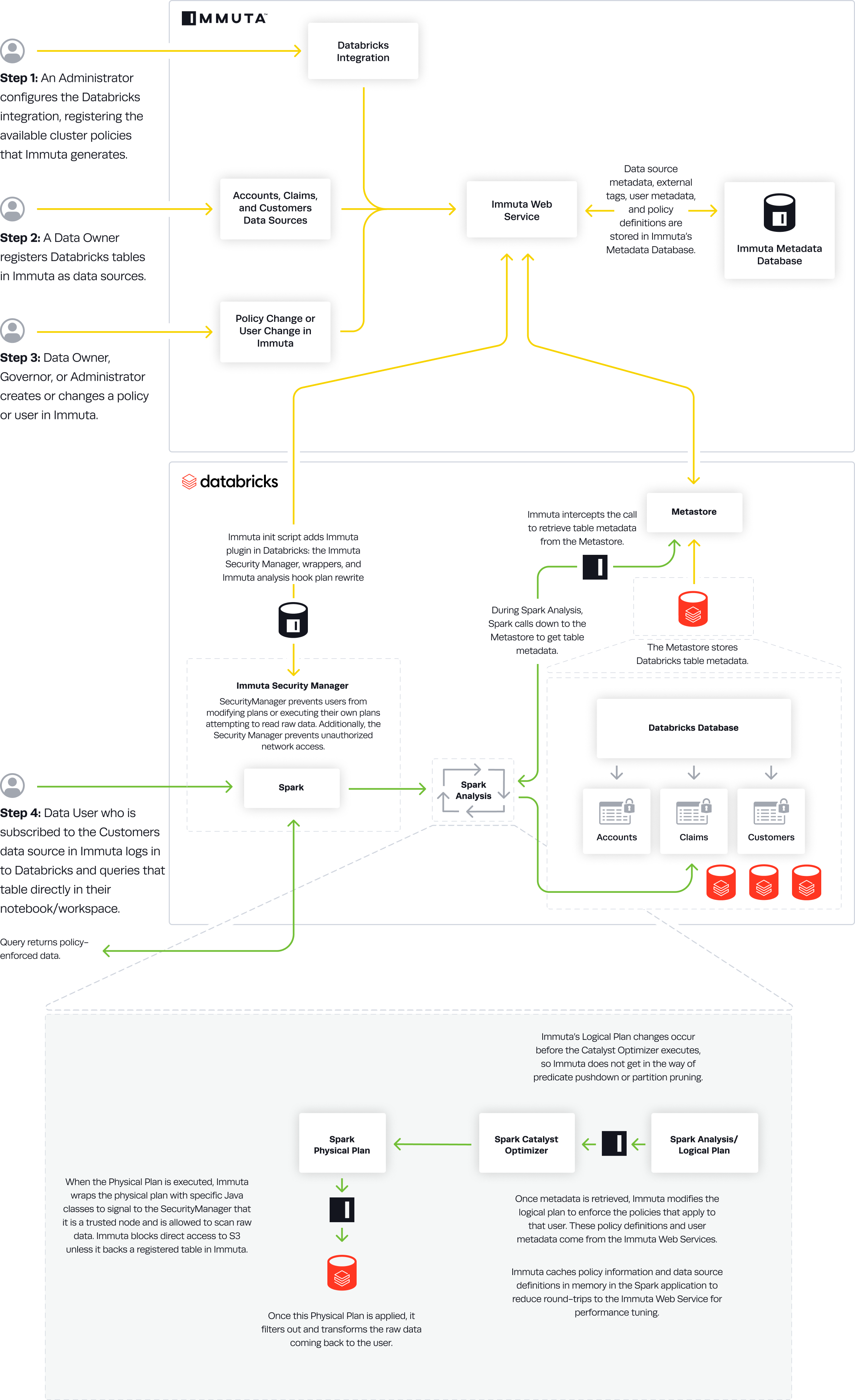
Data Flow
- An Immuta Application Administrator configures the Databricks integration and registers available cluster policies Immuta generates.
- The Immuta init script adds the
immutaplugin in Databricks: the Immuta SecurityManager, wrappers, and Immuta analysis hook plan rewrite. - A Data Owner registers Databricks tables in Immuta as data sources. A Data Owner, Data Governor, or Administrator creates or changes a policy or user in Immuta.
- Data source metadata, tags, user metadata, and policy definitions are stored in Immuta's Metadata Database.
- A Databricks user who is subscribed to the data source in Immuta queries the corresponding table directly in their notebook or workspace.
- During Spark Analysis, Spark calls down to the Metastore to get table metadata.
- Immuta intercepts the call to retrieve table metadata from the Metastore.
- Immuta modifies the Logical Plan to enforce policies that apply to that user.
- Immuta wraps the Physical Plan with specific Java classes to signal to the SecurityManager that it is a trusted node and is allowed to scan raw data.
- The Physical Plan is applied and filters out and transforms raw data coming back to the user.
- The user sees policy-enforced data.