Databricks Roles Best Practices
Intermingling your pre-existing roles in Databricks with Immuta can be confusing at first. Below outlines some best practices on how to think about roles in each platform.
Access to data, platform permissions, and the ability to use clusters and data warehouses are controlled in Databricks Unity Catalog with permissions to individual users or groups. Immuta can control those permissions to grant users permission to read data based on subscription policies.
This section discusses best practices for Databricks Unity Catalog permissions for end-users.
Privileges structure for end-users
Users who consume data (directly in your Databricks workspace or through other applications) need permission to access objects. But permissions are also used to control write, Databricks clusters and warehouses, and other object types that can be registered in Databricks Unity Catalog.
To manage this at scale, Immuta recommends taking a 3-layer approach, where you separate the different permissions into different privileges:
- Privileges for read access (Immuta managed)
- Privileges for write access (optional, soon supported by Immuta)
- Privileges for warehouse and clusters, internal billing
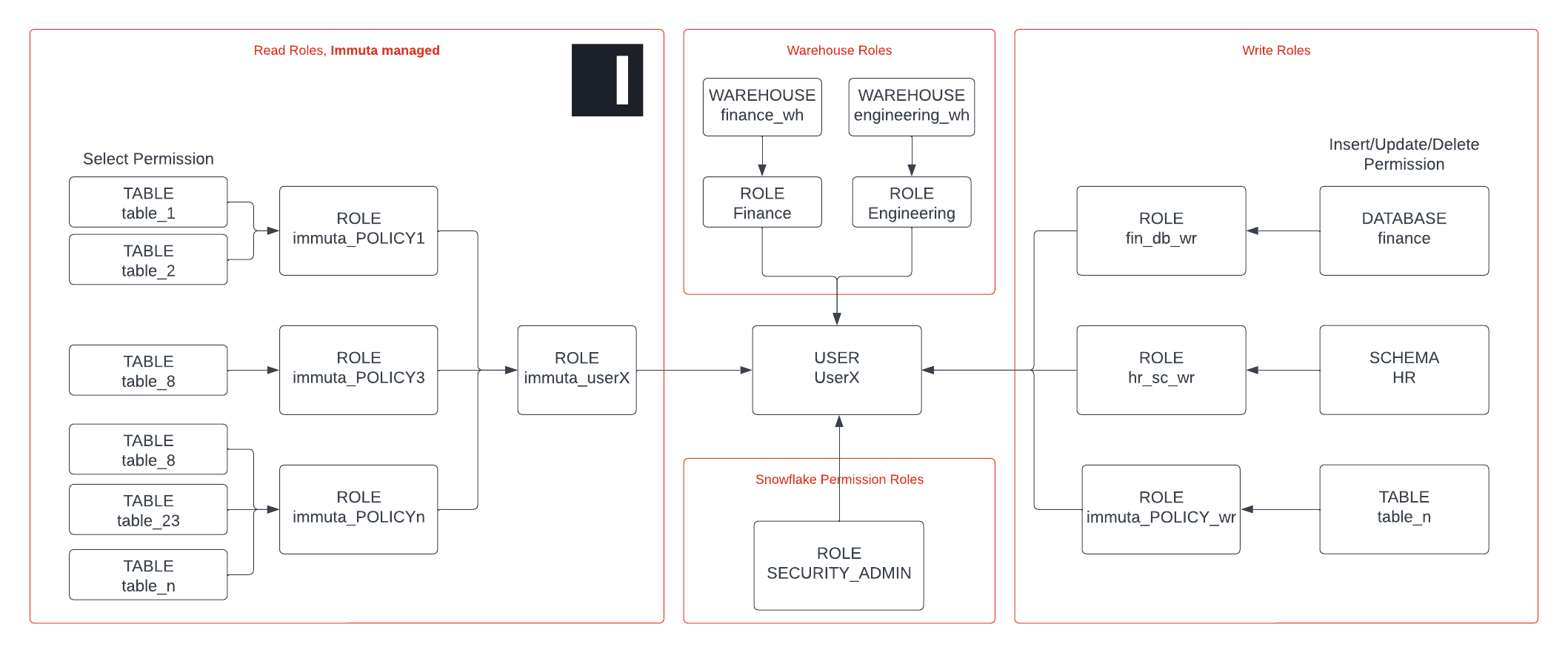
Read access is managed by Immuta. By using subscription policies, data access can be controlled to the table level. Attribute-based table GRANTS help you scale compared to RBAC, where access control is typically done on a schema or catalog level.
Since Immuta leverages native Databricks Unity Catalog GRANTs, you can combine Immuta’s grants with grants done manually in Databricks Unity Catalog. This means you can gradually migrate to an Immuta-protected Databricks workspace.
Write access is typically granted on a schema, catalog, or volume level. This makes it easy to manage in Databricks Unity Catalog through manual grants. We recommend creating groups that give INSERT, UPDATE, or DELETE permissions to a specific schema or catalog and attach this group to a user. This attachment can be done manually or using your identity manager groups. (See the Databricks documentation for details.) Note that Immuta is working toward supporting write policies, so this will not need to be separately managed for long.
Warehouses and clusters are granted to users to give them access to computing resources. Since this is directly tied to Databricks’ consumption model, warehouses and clusters are typically linked to cost centers for (internal) billing purposes. Immuta recommends creating a group per team/domain/cost center, applying this group for cluster/warehouse privileges, and granting this group to users using identity manager groups.
Permission structure for Immuta service principals
Immuta has two types of service accounts to connect to Databricks:
-
Policy role: Immuta needs to use a service principal to be able to push policies to Databricks Unity Catalog and to pull audits to Immuta (optional). This principal needs
USE CATALOGandUSE SCHEMAon all catalogs and schemas, andSELECTandMODIFYon all tables in the metastore managed by Immuta. -
Data ownership role: You will also need a user/principal for the data source registration. A service account/principal is recommended so that when the user moves or leaves the organization, Immuta still has the proper credentials to connect to Databricks Unity Catalog. You can follow one of the two best practices:
- A central role for registration (recommended): It is recommended that you create a service role/user with
SELECT,USE CATALOG, andUSE SCHEMApermissions on all parent catalogs and schemas of tables registered as Immuta data sources. Immuta can register all the tables and views from Databricks, populate the Immuta catalog, and scan the objects for sensitive data using Immuta Discover. Immuta will not apply policy directly by default, so no existing access will be impacted. - A service principal per domain (alternative): Alternatively, if you cannot create a service principal with
SELECT,USE CATALOG, andUSE SCHEMApermissions on all parent catalogs and schemas of tables registered as Immuta data sources, you can allow the different domains or teams in the organization to use a service user/principal scoped to their data. This is delegating metadata registration and aligns well with data mesh type use cases and means every team is responsible for registering their data sets in Immuta.
- A central role for registration (recommended): It is recommended that you create a service role/user with