Data Processing
Terminology: Local Region
The Local Region is the customer's operating region, which determines where an Immuta tenant is deployed and the Immuta Metadata Database lives. Immuta SaaS can deploy in these AWS regions.
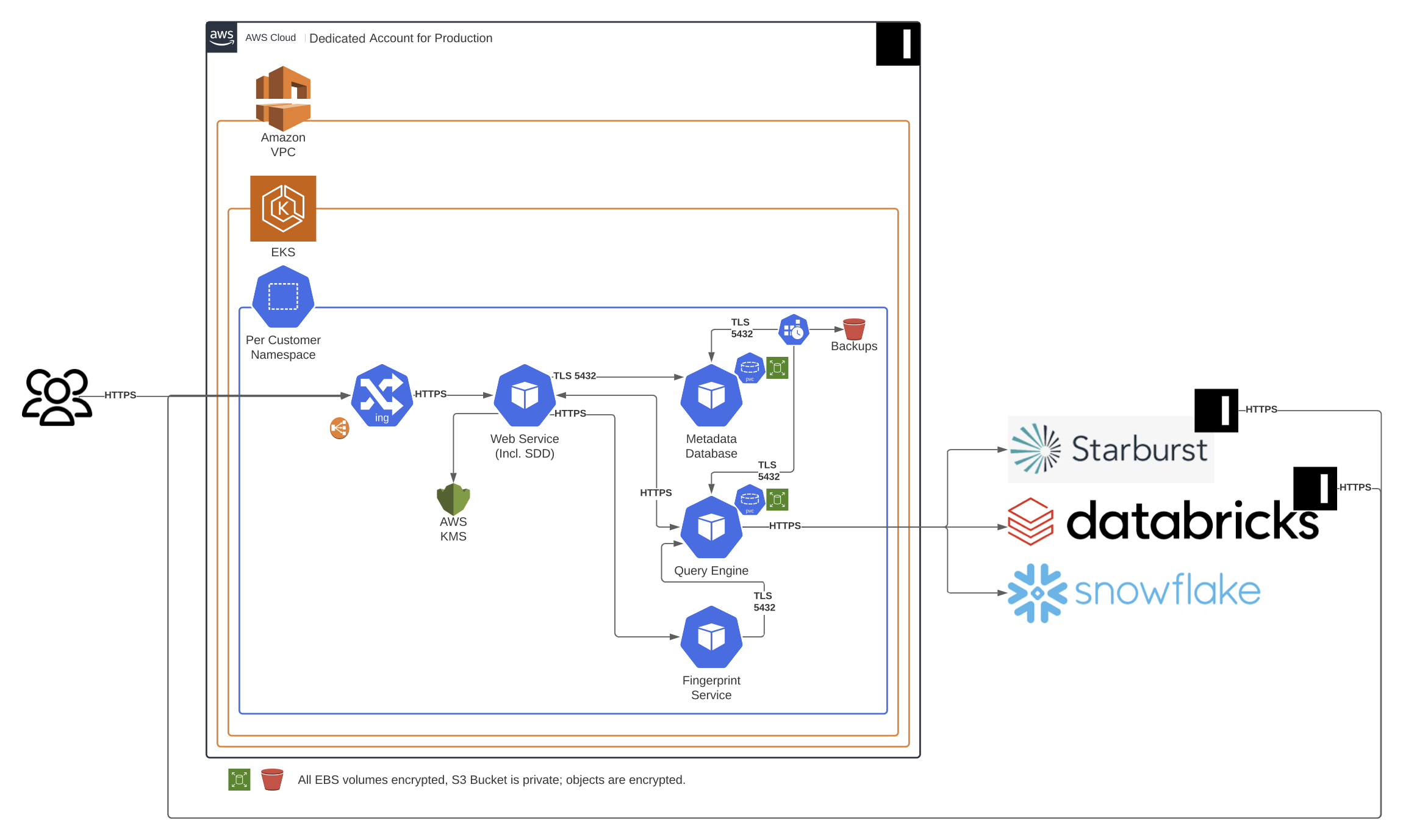
To understand how Immuta processes data, it's imperative to understand the purpose of the Immuta components (illustrated in the diagram below) deployed in the Immuta Cloud infrastructure:
-
Fingerprint Service: When enabled, additional statistical queries made during the health check are distilled into summary statistics, called fingerprints. During this process, statistical query results and data samples (which may contain PII) are temporarily held in memory by the Fingerprint Service.
-
Immuta Accounts Database: Immuta Accounts stores the Immuta tenant's first account as a part of setup. If a customer chooses not to use a third-party identity provider for their user account management, then subsequent Immuta user accounts will be stored here as well. Account information includes name and email address. If desired, a service account may be used to avoid storing personal identifiers.
-
Immuta Tenants Metadata Database: The database specific to a customer's instance that contains the instance's metadata that powers the core functionality of Immuta, including policy data and attributes about data sources (tags, audit data, etc.).
-
Immuta Web Service: This component includes the Immuta UI and API and is responsible for all web-based user interaction with Immuta, metadata ingest, and the data fingerprinting process.
Data Categories
Immuta tenants are localized to the customer.
The Immuta tenants and its components (Metadata Database, Fingerprint Service, and Web Service) are localized to the customer.
Data processed by Immuta falls into one of the following categories. For additional details, click a category to navigate to that section.
| Data Category | Definition | Storage |
|---|---|---|
| Immuta Audit Logs | Audit logs include details about data access, such as who subscribes to a data source, when they access the data, and the queries they've run. | This data is stored in the instance's Metadata Database. |
| Immuta Identity Manager Data | This data includes user account data, such as email addresses, names, and entitlements. | This data is stored in the instance's Metadata Database and in Immuta Accounts (single, US-based region), unless a customer has opted to use an external identity provider. |
| Data Dictionary and Data Source Metadata | This data includes column names, tags, free-text descriptions of columns, and health check results, such as row counts and high cardinality checks. Additionally, this data source metadata may include the schema, column data types, and information about the host. | This data is stored in the instance's Metadata Database. |
| Data Source Summary Statistics | This data includes summary statistics regarding changes to data sources, including when policies have been applied, when external views have been created, when sensitive data elements have been added, and when users have enabled checks for new tables through schema monitoring. | This data is stored in the instance's Metadata Database. |
| Policy Definition Data | This data includes the metadata (such as usernames, group information, or other kinds of personal identifiers) sent to the Immuta Web Service to determine if a user has access. When such information is relevant for access determination, it may be retained as part of the policy definition. | This data is stored in the Metadata Database. |
| Sample Raw Data | Data that is processed and aggregated/reduced as a part of the Immuta fingerprinting process and specific policy processes. | Data exists temporarily in memory in the Fingerprint Service. |
| User Metrics Data | This data includes instance metrics -- statistics about activities occurring within Immuta, such as how many policies, projects, or tags have been created and how many users are authenticated within Immuta -- and user metrics, such as the user and session and event properties (user and session IDs, page views, and clicks). | This data is stored in a single, US-based region. |
TCP Connection
Immuta communicates with remote databases over a TCP connection.
Immuta Audit Logs
Audit data includes metadata (e.g., who subscribes to a data source, when they access data, potentially what SQL queries were run, etc.) that is generated by a variety of actions and processes in Immuta. The most common processes are illustrated in the diagram below.
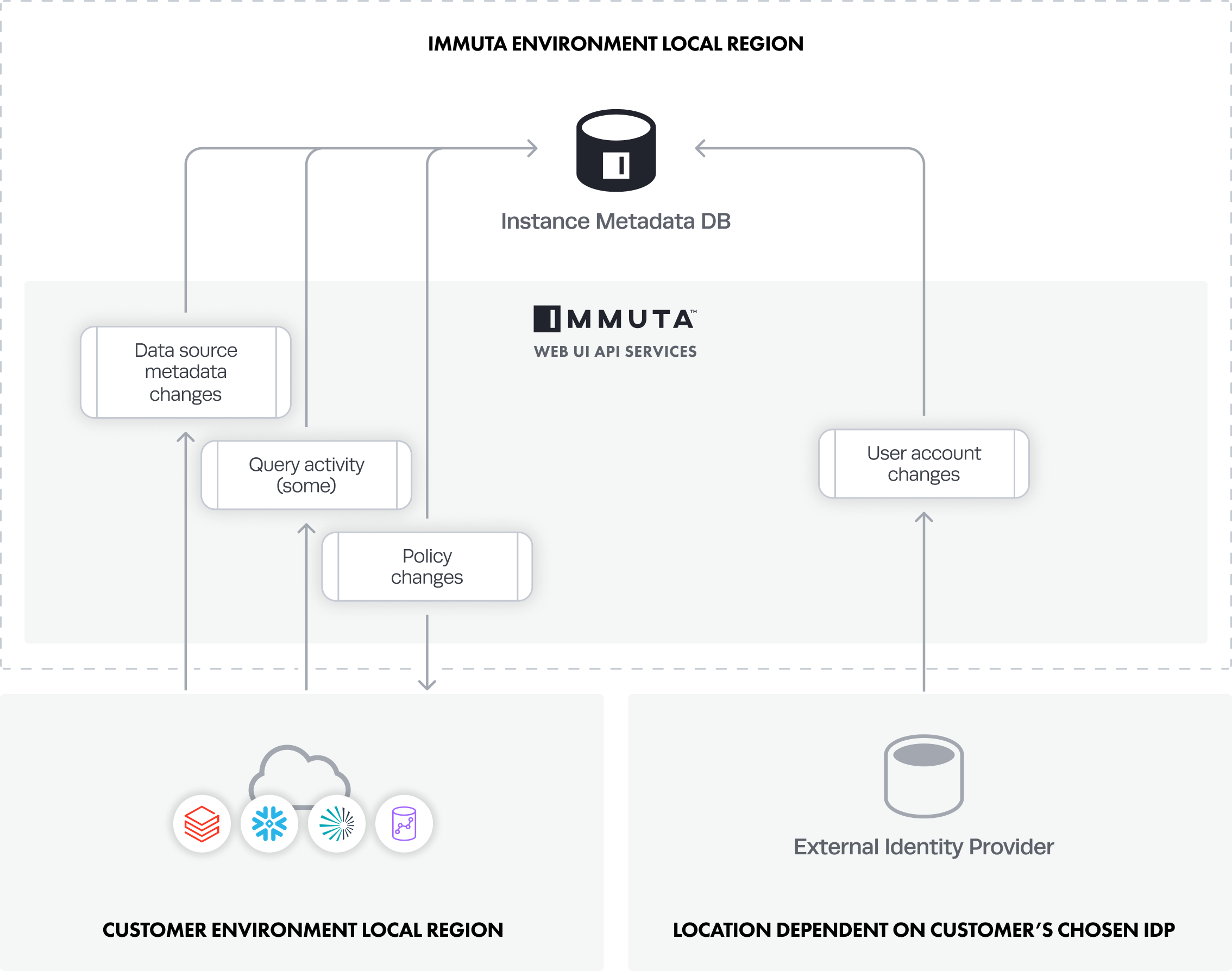
All audit logs flow from the Web Service to the Metadata Database (local to the customer's region) and are stored for 90 days.
Immuta Identity Management Data
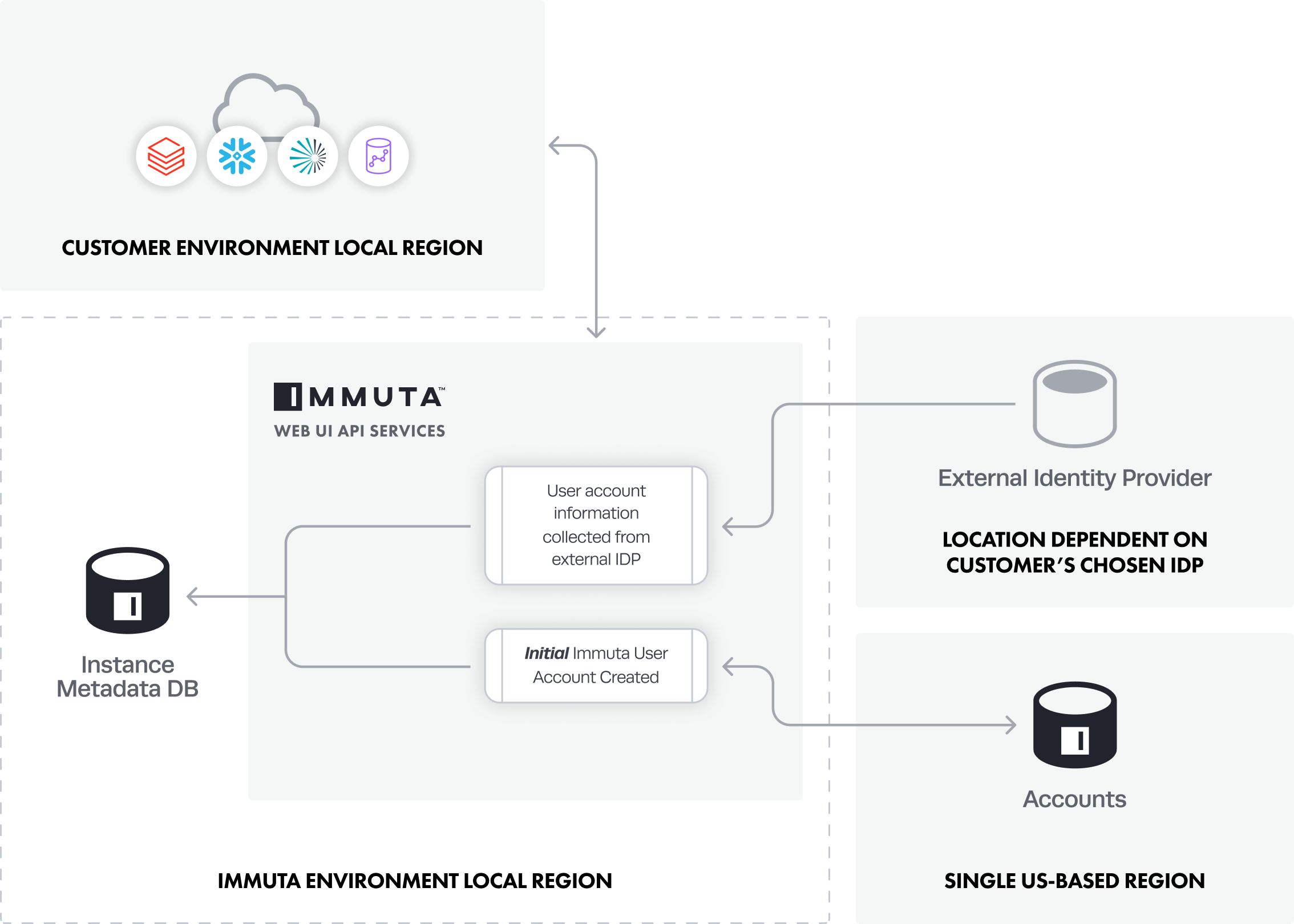
This process is only relevant to customers using an external identity provider service to manage user accounts in Immuta.
- The initial Immuta user account is created through Immuta Accounts, and this data is stored in the US (AWS us-east-1).
- A System Administrator configures an external IAM with Immuta.
- User account information is collected from the external IAM and stored in the instance's Metadata Database.
](img/saas-iam-data.png)
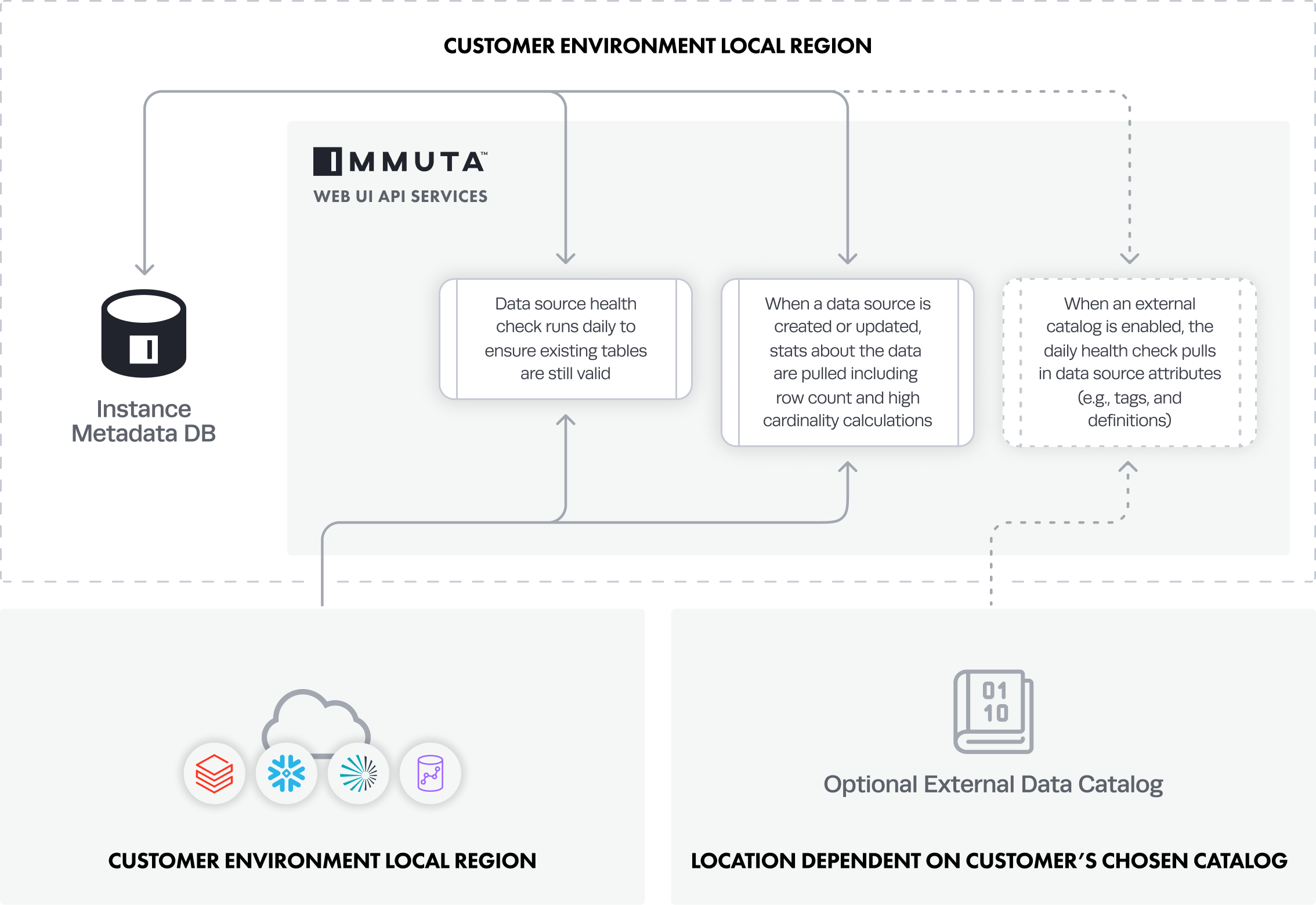
Data Dictionary and Data Source Metadata
This data is processed to support data source creation, health checks, policy enforcement, and dictionary features.
- A System Administrator configures the integration in Immuta.
- A Data Owner registers data sources from their remote data platform with Immuta. Note: Data Owners can see sample data when editing a data source. However, this action requires the database password, and the small sample of data visible is only displayed in the UI and is not stored in Immuta.
- When a data source is created or updated, the Metadata Database pulls in and stores statistics about the data source, including row count and high cardinality calculations.
- The data source health check runs daily to ensure existing tables are still valid.
- If an external catalog is enabled, the daily health check will pull in data source attributes (e.g., tags and definitions) and store them in the Metadata Database.
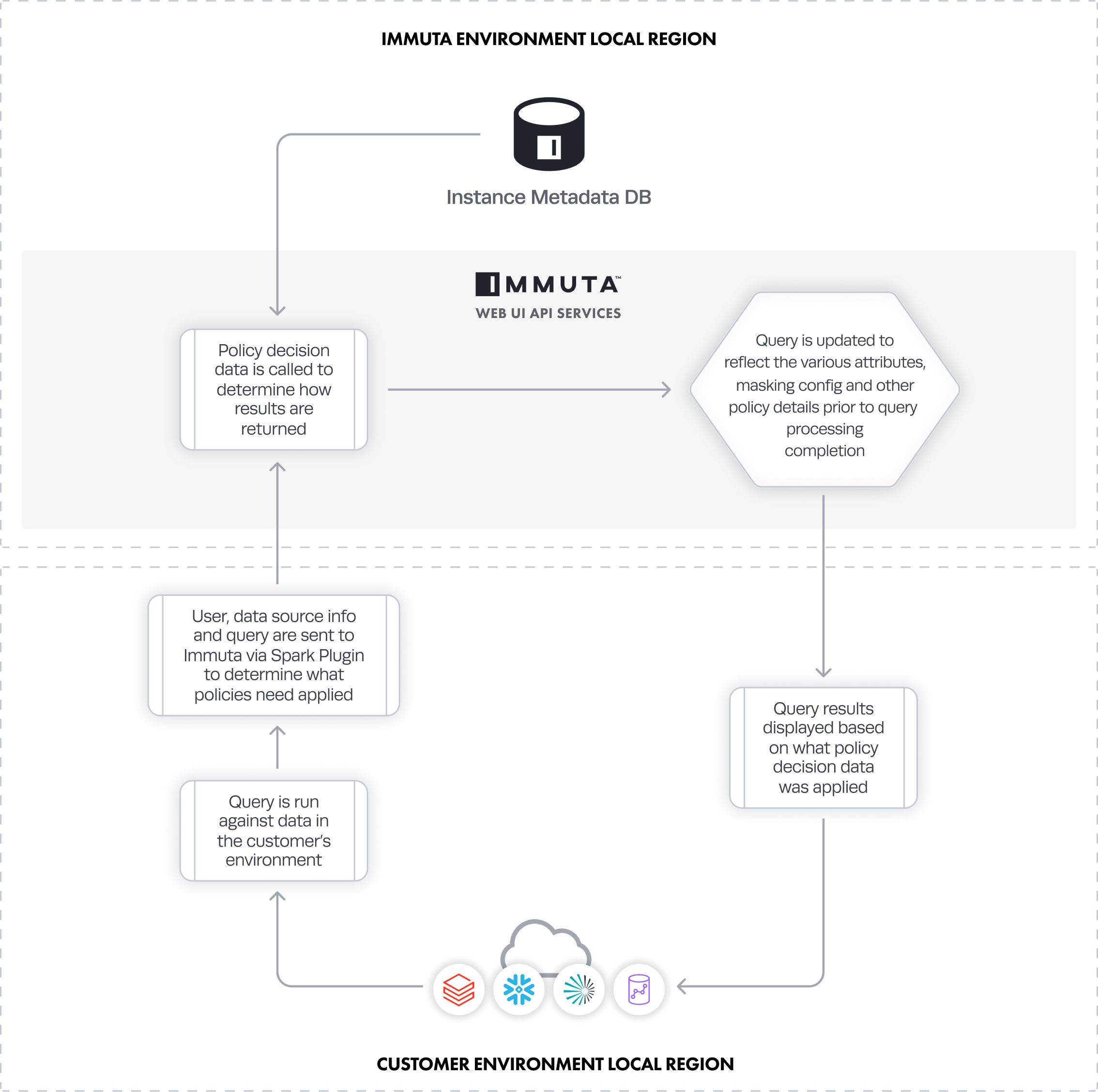
Policy Decision Data
Policy decision data is transmitted to ensure end users querying data are limited to the appropriate access as defined by the policies in Immuta.
Spark Plugin
In the Databricks integration, the user, data source information, and query are sent to Immuta through the Spark Plugin to determine what policies need to be applied while the query is being processed. Data that travels from Immuta to the Databricks cluster could include
- user attributes.
- what columns to mask.
- the entire predicate itself (for row-level policies).
- A user runs a query against data in their environment.
- The query is sent to the Immuta Web Service.
- The Web Service queries the Metadata Database to obtain the policy definition, which includes data source metadata (tags, column names, etc.) and user entitlements (groups and attributes).
- The policy information is transmitted to the remote data system for native policy enforcement.
- Query results are displayed based on what policy definition was applied.
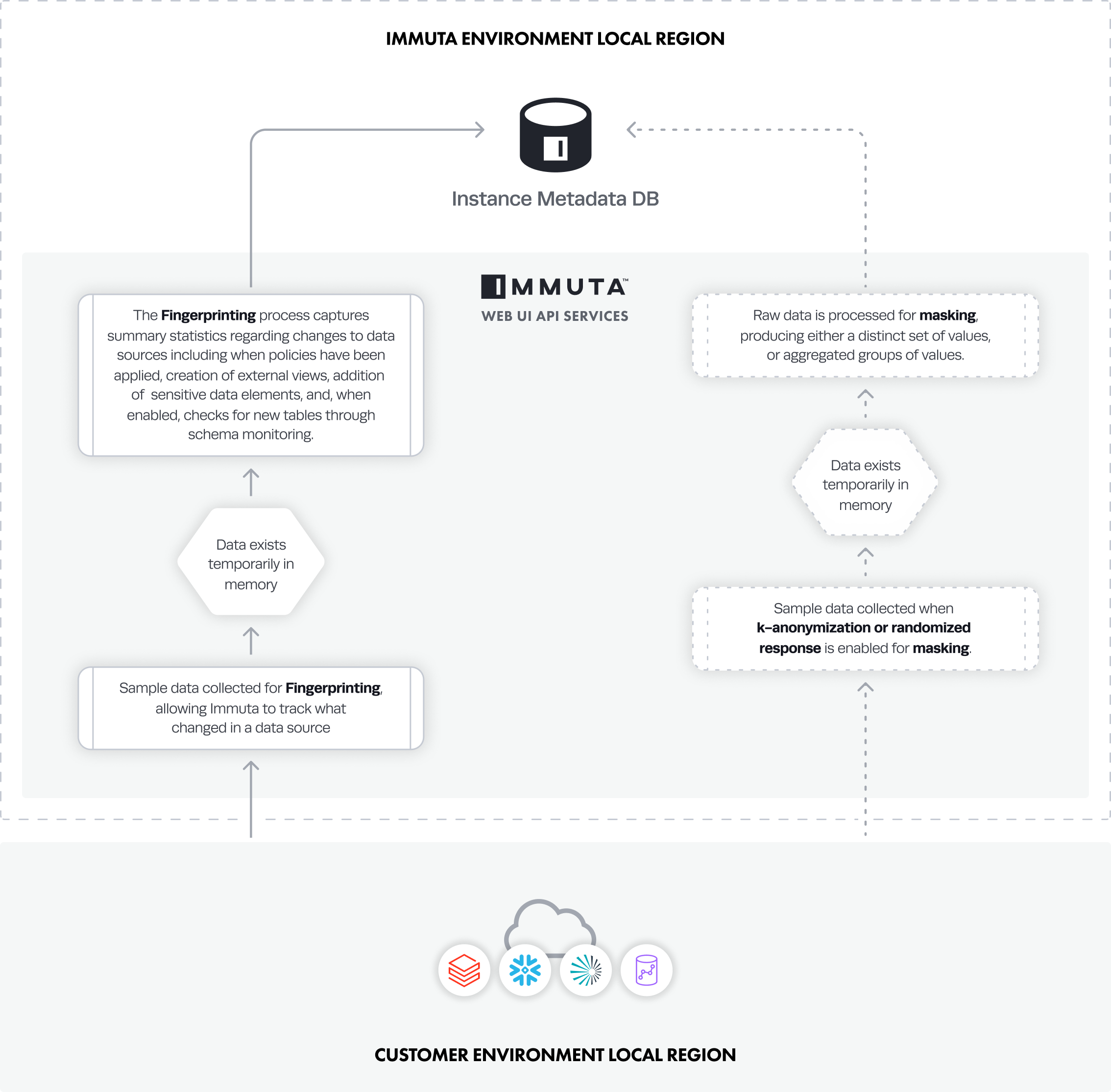
Sample Raw Data
Sample data is processed and aggregated or reduced during Immuta's fingerprinting process and specific policy processes. Note: Data Owners can see sample data when editing a data source. However, this action requires the database password, and the small sample of data visible is only displayed in the UI and is not stored in Immuta.
Fingerprinting Process
-
When enabled, statistical queries made during data source registration are distilled into summary statistics, called fingerprints. Fingerprinting allows Immuta to implement advanced privacy enhancing masking and data policies.
-
During this process, statistical query results and data samples (which may contain PII) are temporarily held in memory by the Fingerprint Service only for the amount of time it takes to calculate the statistics needed. For Snowflake, no data sample is needed, and only statistics about the data are returned to Immuta (no PII).
-
The fingerprinting process checks for new tables through schema monitoring (when enabled) and captures summary statistics of changes to data sources, including when policies were applied, external views were created, or sensitive data elements were added.
Policy Processes
Immuta does not sample data for row-level policies.
Immuta does not sample data for row-level policies; Immuta only pulls samples of data to determine if a column is a candidate for randomized response and aggregates of user-defined cohorts for k-anonymization. Both datasets only exist in memory during the computation.
- Sample data is processed when k-anonymization or randomized response policies are applied to data sources.
- Sample data exists temporarily in memory in the Fingerprint Service during the computation.
- k-Anonymization Policies: At the time of its application, the columns of a k-anonymization policy are queried under a separate fingerprinting process that generates rules enforcing k-anonymity. The results of this query, which may contain PII, are temporarily held in memory by the Fingerprint Service. The final rules are stored in the Metadata Database as the policy definition for enforcement. Immuta requires that you opt in to use this masking policy type. To enable k-anonymization for your account, contact your Immuta representative.
- Randomized Response Policies: If the list of substitution values for a categorical column is not part of the policy specification (e.g., when specified via the API), a list is obtained via query and merged into the policy definition in the Metadata Database.
- Raw data is processed for masking, producing either a distinct set of values or aggregated groups of values.
User Metrics Data
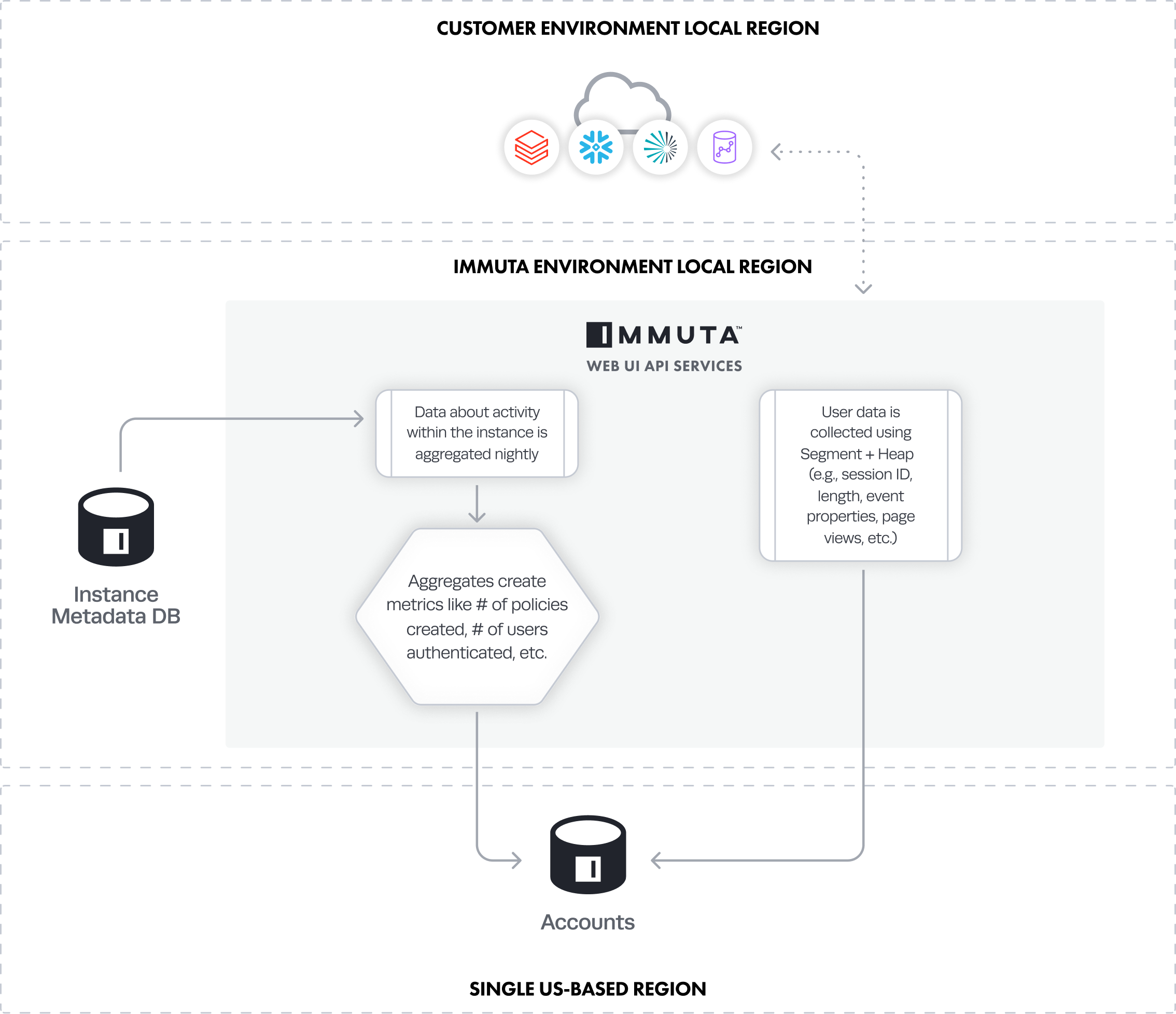
Immuta collects a variety of metrics and details about app usage that is stored in a single US-based region.
- Data about activity within the instance is aggregated nightly.
- Aggregates create metrics (the number of policies created, number of users authenticated, number of tags created, etc.).
- User data (session ID, length, event properties, page views, etc.) is collected using Segment and Heap.
- All of this data is stored in a single, US-based region (AWS us-east-1).